This is one of the projects that I worked on with Ling Jin (@ljin8118) and Peter Schmidt (@pjschmidt007)as a part of our Text Analytics course at Northwestern University. It was one of the most exciting projects to have worked on and in the process learnt the latest and cutting edge techniques used in the field of Text Analytics and Text Mining. Hope you will enjoy it as much as we enjoyed doing it! Cheers 🙂
Goal
Provide a textual analysis of the movie script, The Dark Knight, which was robbed of the best picture Oscar at the 81st Annual Academy Awards on February 22, 2009. All project team members are still bitter about this fact. This assignment hopes to resurrect the greatness that is The Dark Knight.
More seriously though, if given a script, the text analytics conducted in this assignment would be able to produce insights into the genre, mood, plot, theme and characters. Ideally the analysis is intended to understand and answer the who, what, when, where and why in regards to a movie.
Objectives
Specifically, the objectives of the textual analysis of The Dark Knight will cover:
- Determine the major characters in the script
- Show the character to character interaction
- Provide insights into sentiment by character
- Show how sentiment changes over time
- Determine major themes/topics of the script
Approach

Processing Steps
- Acquire the movie script of choice
- Parse the script into lines by scenes and lines by character
- Tokenize, normalize, stem the lines of dialogue as appropriate
- Build an index based on available components for subsequent queries
- Perform part of speech (POS) Tagging on the lines of dialogue
- From the POS Tagging, perform sentiment scoring on the lines of dialogue
- Perform named entity recognition
- Perform co-reference
- Perform topic modeling
- Analyze results
- Produce visualizations
Results
Character Identification


The above two visuals carry the same information, just two different representations, about the important characters in the movie. The first visual is a Bubble chart where the size of the bubble is proportional to the # of lines said by the character.
The second one is a Heat map diagram where again, the area represents the quantity of lines of dialogue across scenes by characters. These two visuals help us identify the major characters of the movie. One can see that Harvey Dent (aka Two-Face), Gordon, The Joker, Bruce Wayne, Batman, Rachel, Fox, and Alfred were easily the major characters of the movie, with Lau, Chechen, Maroni and Ramirez all playing supporting roles. It is interesting to note that in the script, Two-Face is never named as a separate character, unlike Bruce Wayne and Batman. Combining Bruce Wayne and Batman’s line would have made him the most prominent character over Harvey Dent.
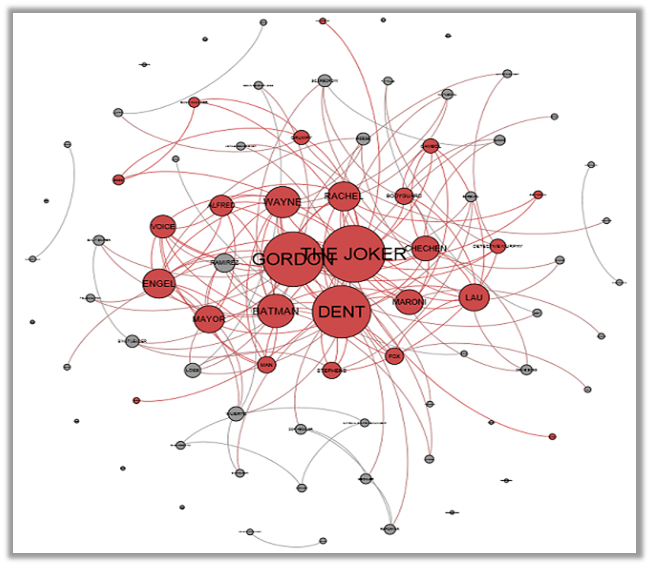
Character Interactions

Now that the major characters are established, the next obvious step would be to identify how these characters interact with each other.
The above visual gives us an insight into this. Each node is a character and each edge tells us that the two nodes connected by that edge have interacted at least once in the movie. Our definition of interaction is when two or more characters speak in a single scene. Hence more the number of interactions with distinct characters, bigger will be the size of the node.
The nodes (characters) marked in Red are the central characters. Most of the characters whom have a lot of dialogues also have more interactions with distinct characters. But are there some exceptions, i.e. are there characters who have a lot of lines but less interactions (may be someone like Alfred – having watched the movie) or vice versa? Let’s look further to see what was observed.
Sentiment over time
Below is a visual description of the sentiment of the scenes over time. The methodology to calculate the sentiment for each scene was to first split each scene into dialogues by individuals. Then each dialogue was run through the Design process explained above. At the end of it we get a score for each dialogue and an average of senti scores of all these dialogues gave us the senti score of the scene. As we can see, this was a dark dark movie.

We also looked how character sentiment varied over time. Again the methodology to calculate this was similar to the one above, but this is by character and not by scene.

BATMAN vs. JOKER
What does the Batman say?

As the superhero in this movie, Batman does not talk that much (based on the IDENTIFICATION OF IMPORTANT CHARACTERS and part the real movie). He does mention his opponents, all the killings and of course the word “hero
What does the Joker say?

The joker talks quite often actually, which was confirmed earlier. He talks about his scar /the smile, his childhood and the whole plan stuff. He also mentions all the names quite often.
Design and Implementation Challenges
Script
One of the first things was to find an appropriate script, which turned out to be a little harder than expected. It was sort of like finding a needle in a haystack. But after some perseverance, The Dark Knight Script was found at:
http://www.pages.drexel.edu/~ina22/splaylib/Screenplay-Dark_Knight.HTM
There were 8704 actual lines that needed to be parsed and fit together in the above script.
Parsing
There were several nuances that needed to be taken into consideration for the actual script parsing. First of all, the script that was found was not broken down by multiple html tags representing the different portions of the script. Instead, the entire script was basically under one tag, which meant parsing was for an entire block of unstructured text. Hence we had to carefully find patterns and parse the script.
Tokenization and Lemmatization
The Standard Analyzer in the Stanford NLP was chosen to handle the tokenization and any normalization required. It also provided lower case and stop word filtering. As it was decided that stemming was not going to be necessary for the analysis that was to be conducted, the Standard Analyzer was chosen over the English Analyzer as the aggressive stemming performed by the PorterStemFilter was not necessary to support the other downstream pipeline processes. The Standard Analyzer was then used consistently across the pipeline to prevent any inconsistency concerns.
POS and Sentiment
There were a couple of options available to perform sentiment mining on the dialogue in the script.
Option 1:
The initial selection was to use SentiWordNet, http://sentiwordnet.isti.cnr.it SentiWordNet is a lexical resource that is based on WordNet 3.0, http://wordnet.princeton.edu and is used for opinion mining. SentiWordNet assigns a score to each synset, defined as a set of one or more synonyms, of a word for a particular part of speech. The parts of speech in SentiWordNet are defined as:
a = adjective
n = noun
r = adverb
v = verb
Obtaining the parts of speech from the Stanford NLP part of speech annotator would then require mapping from the parts of speed defined in the Penn Tree Bank Tag set, http://www.computing.dcu.ie/~acahill/tagset.html, to the part of speech defined in SentiWordNet so that a sentiment score could be produced.
The SentiWordNet resource is constructed as follows:
POS = part of speech
ID = along with pos, uniquely identifies a WordNet (3.0) sunset.
PosScore = the positivity score assigned by SentiWordNet to the synset.
NegScore = the negativity score assigned by SentiWordNet to the synset.
SynsetTerms = terms, including the sense number, belonging to the sunset
Gloss = glossary
Note: The objectivity score can be calculated as: ObjScore = 1 – (PosScore + NegScore)
Option 2
Another option instead of SentiWordNet was to use the sentiment annotator in the Standford NLP pipeline. The team discovered this new addition to the Stanford NLP during the course of the project. It is recent “bleeding edge” sentiment technology that Stanford is now including the Stanford NLP. Excerpted from there website, as most sentiment prediction systems work just by looking at words in isolation, giving positive points for positive words and negative points for negative words and then summing up these points. Which by the way in essence is what we were doing. That way, the order of words is ignored and important information is lost. In contrast, the sentiment annotation that is part of the Stanford NLP institutes a new deep learning model that builds up a representation of whole sentences based on the sentence structure, computing the sentiment based on how words compose the meaning of longer phrases. There are 5 classes of sentiment classification: very negative, negative, neutral, positive, and very positive.
Sentiment Scoring
There were several methods available in calculating a sentiment for character lines in a given scene. This is due to the fact that the actual “sense” of the word was not known when passed to the parser to do the actual sentiment. So if “good” had n-senses in the lexical resource, it was not known which sense was used in the dialogue.
Method 1
The first method was to sum all the senti scores within the body of text then divide by the sum of all scores. This was the method that was provided in the demo on the SentiWordNet web site.
Method 2
The second method was to sum all the senti scores within the body of text then divide by the count of all scores.
Method 3
The third method was to just sum all the senti scores within the body of text. Although we actually implemented both options for obtaining sentiment (i.e SentiWordNet and Stanford NLP sentiment annotation), the option that was chosen to score the dialogue was SentiWordNet. The scoring method that was then used, although each were explored, was method 2 defined above. This is the method we finally decided to use in our sentiment analysis of the script.
Concluding Remarks
Text analytics is quite the involved process. As with most data analysis activities a major portion of the time is spent identifying, acquiring and cleansing the source data. The field of text analytics is quite broad with many best of breed components. However, text analytics does not have well integrated toolsets, so you can observe from the solution that was crafted in having to leverage several technologies (Java, R, Excel, Gephi, Tableau) using different libraries (Stanford NLP, Lucene) and various other packages to perform specific functions within the data pipeline. All in all, though, it has been shown that with some blood, sweat and tears (over 1200 lines of code were written for this assignment), and by all means time, a text analytics tool can be built to analyze movie scripts with a pretty accurate view when compared to the overall reality of the movie. And lastly, it should be mentioned, then the inherent complexities in the dialogue and the richness of the script should have guaranteed the Oscar for The Dark Knight!

WHY SO SERIOUS?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}